
RAG是什么
RAG 是 Retrieval-Augmented Generation(检索增强生成) 的缩写,指的是一种把「外部知识检索」和「大模型生成」结合起来的技术:在模型回答问题前,先从数据库、文档或向量库中检索出最相关的资料,再基于这些真实资料来生成回答,这样可以减少“瞎编”、提高准确性,还能让模型使用最新或私有数据,因此常用于知识库问答、企业内部文档助手、论文/代码辅助等场景。
RAG全流程
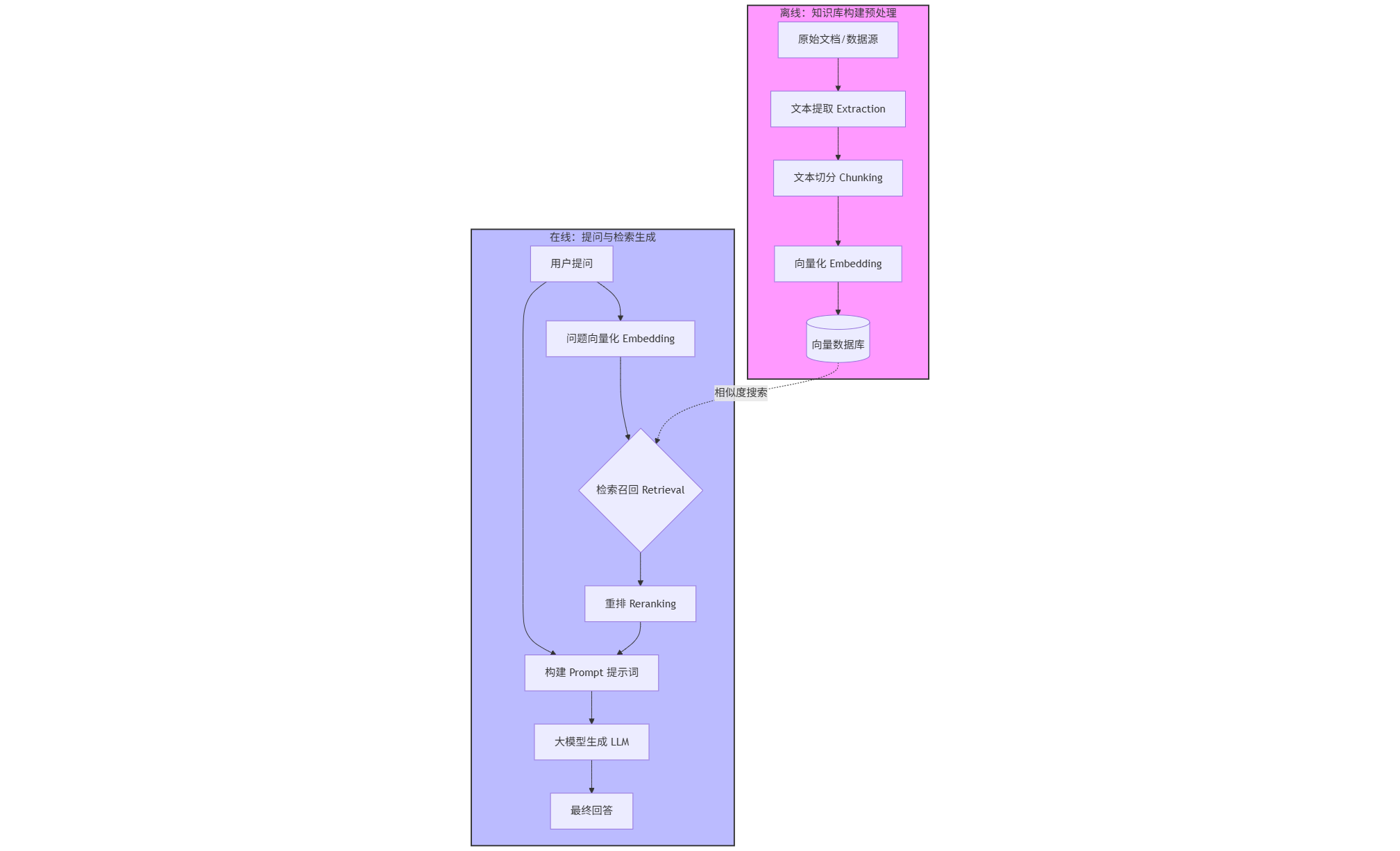
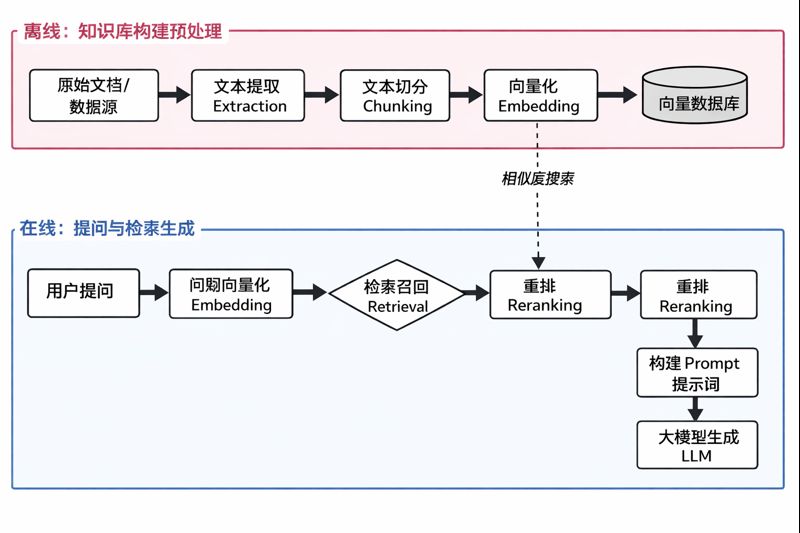
1、准备知识库
收集资料:收集与安全知识相关的文档、手册、FAQ等资料。
1️⃣ 安全操作规程
起重机安全操作规程、吊装作业规范、设备检查制度2️⃣ 事故案例
起重机倾覆事故、违章操作事故、典型事故分析报告3️⃣ 管理制度
安全生产责任制、作业许可制度、人员培训制度4️⃣ 应急处置
起重机事故应急预案、人员伤害处置流程、设备故障应急方案
2、文本预处理
在将原始文档导入数据库之前,需要对文本进行清洗和标准化处理,以提高检索和生成的准确性。这包括:
- 剔除页码、页眉页脚等无关信息
- 修复断句问题(如将非标点结尾的换行符替换为空格)
- 规范化空白字符(如多个空格合并为一个)
- 保留关键术语和结构信息
1 | import pdfplumber |
3、文本切分
将清洗后的长文本切分成更小的片段,以便后续的嵌入和检索。常用的方法有基于句子、段落或固定长度的滑动窗口切分。以下是一个示例代码,展示如何使用LangChain进行文本切分:
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
以上的代码展示了文本切分的基本流程。使用
RecursiveCharacterTextSplitter可以根据指定的块大小和重叠度,将长文本切分成多个知识块,方便后续的嵌入和检索。可以根据实际需求调整chunk_size和chunk_overlap参数,以获得最佳的切分效果。
4、向量化与存储
将切分后的文本块转换为向量表示,并存储在向量数据库中,方便后续的相似度检索。
1 | import os |
使用
HuggingFaceEmbeddings将文本块转换为向量表示,并使用Chroma向量数据库进行存储。代码中包含了进度条显示,方便监控入库过程。HuggingFaceEmbeddings模型将文本转化为向量的维度为768。
1. Embedding 模型:shibing624/text2vec-base-chinese
这是一个专门针对中文语义优化的开源模型,基于 BERT 架构进行改进.
- 向量维度:768 维。 这意味着它会将你每一段 500 字左右的起重机规程,编码成一个包含 768 个浮点数的数学列表。这 768 个维度分别代表了文本在语义空间中的不同特征。
- 核心原理:它通过在大规模中文语料(百科、新闻、论文)上进行预训练,学习到了词与词、句与句之间的“亲密度”。
- 例如:它能识别出“吊钩”和“索具”在空间坐标上非常接近,而与“冰激凌”相距甚远。
- 为什么选它?
- 中文支持极佳:比很多多语言模型更能理解“起重机”、“溜钩”、“下挠”等专业词汇。
- 性能平衡:768 维是目前工业界的“黄金维度”,既保留了足够的语义精度,计算速度又比 1024 或 1536 维的模型快得多。
2. 向量数据库:ChromaDB
ChromaDB是目前 AI 开发社区最流行的开源嵌入式向量数据库。你可以把它想象成一个专门存储“坐标”和“标签”的高级 Excel。
核心特性:
- 存储机制:它属于持久化本地存储。在你的项目目录下生成的 chroma_db 文件夹,实际上包含了向量数据索引和 SQLite 数据库(用于存储原始文本和元数据)。
- 检索算法 (HNSW): 它使用的是 HNSW (Hierarchical Navigable Small World) 算法。这是一种“小世界”图算法。
- 形象比喻:它不像传统的数据库那样一行行去查,而是像在朋友圈里找人一样,通过层层关联的“节点”快速定位到最接近的向量。
- 元数据过滤 (Metadata Filtering): 我们在代码里存入的 source(文件名)就存在这里。这让你不仅能搜到内容,还能瞬间知道它出自哪本 PDF。
| 组件名称 | 具体选型 | 关键参数 | 作用 |
|---|---|---|---|
| Embedding 模型 | text2vec-base-chinese | 向量维度:768 | 将规程文本转化为数学向量 |
| 向量数据库 | ChromaDB | 算法:HNSW 距离度量:L2 |
存储向量并实现快速语义检索 |
| 文本处理 | LangChain | Chunk Size:600 Overlap:100 |
保证知识块语义完整 |
5、构建问答系统
利用向量数据库实现基于内容的检索,并结合大语言模型生成回答。
1 | import os |
使用Gemini 2.5 Flash模型进行回答生成。系统提示词中明确要求模型基于检索到的起重机规程和案例进行回答,避免“瞎编”。同时,回答中会附上参考的文件来源,提升可信度。
新建.env文件,添加环境变量。在.env文件中写入:GEMINI_API_KEY=你的API密钥
将用户的问题使用相同的embedding模型转换为向量,并在ChromaDB向量数据库中进行相似度搜索,找到最相关的3个知识块作为上下文。相似度搜索使用的是L2距离度量。
L2距离度量:
公式中参数解释:
- (d):表示查询向量 (q) 和存储向量 (v) 之间的 L2 距离。
- (n):表示向量的维度(在本例中为768维)。
- (q_i):表示查询向量 (q) 在第 (i) 个维度的值。
- (v_i):表示存储向量 (v) 在第 (i) 个维度的值。


- 本文作者: Apezer
- 本文链接: http://example.com/2026/01/14/基于LLM与RAG的安全知识问答系统开发笔记/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
 GitHub
GitHub